What is Open Discover™ SDK?
It is a .NET developer toolkit that developers use to:
- Identify document file formats using internal binary signatures versus using unreliable file extensions.
- Extract text from documents (e.g., Office documents and emails) and optionally identify language regions present in extracted text
- Extract metadata (supports custom user metadata)
- Identify document attributes (e.g., ‘WorksheetHasHiddenColumns’ document attribute)
- Extract attachments and embedded objects from documents
- Calculate MD5/SHA-1 hashes of raw document bytes and also calculate a sophisticated "ContentHash" for supported document formats. The "ContentHash" is supported on emails (.MSG,.EML,.EMLX,.DXL) and Microsoft Office documents (DOC, PPT, XLS, DOCX, PPTX, XLSX) and is a hash of uniquely identifying document content. These hashes are useful for de-duplicating documents, that is, allowing users to identify, group, and/or remove duplicate documents from a document set.
- Extract items from archive container formats (7ZIP, ZIP, RAR, TAR, and many other formats). Supports extraction from encrypted archives if user has valid password.
- Extract emails from email container formats (PST, OST, OST2013, MBOX)
Before indexing a document for full-text search or using machine learning classification on a set of documents, you first need to get document text, metadata, and that of any document attachments. For this reason, Open Discover™ SDK is useful companion toolset for:
- machine learning
- full-text indexing
- file storage document identification and de-duplication
- ECM systems
- eDiscovery
- and more.
The SDK can identify 1,400+ document file formats. The SDK does not rely on file extensions to identify file formats except for a few cases (described below), the SDK uses binary or other unique internal signatures of a document to identify its file format.
To identify a document, using C#/.NET code, is as simple as:
- where method argument ‘_stream’ is an open .NET Stream object (e.g., FileStream or MemoryStream)
- where method argument ‘filename’ is the filename or full path of file with extension (if it exists).
It is not necessary to pass in filename as an argument but is strongly recommended. Some file formats such as encrypted Microsoft Office 2007-2016 documents have the same file format and same internal signatures and cannot be 100% identified until the internal package hosting the real document is decrypted. In cases such as these, and a few other special cases, the file extension is used in conjunction with the internal signatures to identify the document.
In the example code snippet above, the returned result ‘docIdResult’ is an IdResult object (see class diagram below) that specifies the identified file format (property name "ID" which is of enumerated type Id, ex: Id. OutlookMessage, Id.Excel2007Encrypted, etc.), the classification of the document format (property name "Classification" which is of enumerated type ‘IdClassification’, ex: IdClassification.Email, IdClassification.Spreadsheet, IdClassification.WordProcessing, etc.), Media Type (MIME type) if known, the character set encoding if a text based document format, text description of the file format, and more.
The SDK can extract content from nearly 600 document file formats and growing (counted by document file format ID). For document types that aren’t supported, a fast and accurate binary-to-text filter extractor is provided that allows useful text, if any present, in UTF8, UTF16, and code page 1252 encodings to be extracted from the document's binary (only "Latin" encodings are extracted for UTF16 and code page 1252 encodings)
To extract content from a document, using C#/.NET code, we make a method call to the content extractor factory that makes use of the identified document format to return an appropriate extraction interface for that particular format:
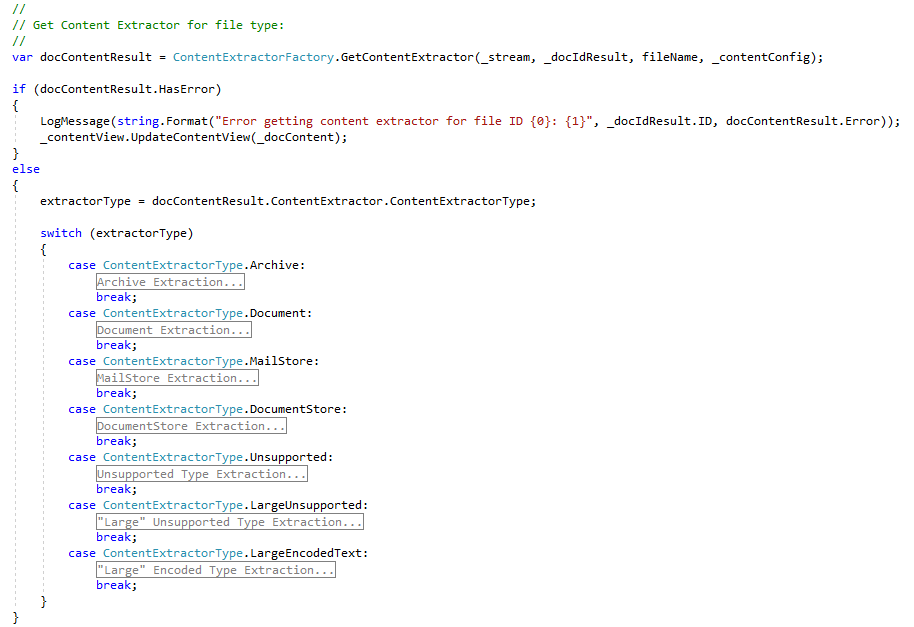
- where method argument ‘_stream’ is an open Stream object (FileStream or MemoryStream) to the document;
- where argument ‘_docIdResult’ is the document identification result returned in the earlier code snippet;
- where ‘filename’ is the filename or full path of file with extension (if it exists);
- where ‘_contentConfig’ is a ContentExtractionSettings object that has setting options for what is extracted (e.g., only extract metadata, or to extract text, metadata, and attachments/embedded objects) and options for hashing, language identification of extracted text, etc.
In the example code snippet above, the returned ‘docContentResult’ result object is a ContentExtractorResult object from which the user can get the appropriate interface to extract content for the document’s particular file format. Archives, mail stores, and office documents have their own distinct extraction interface types.
The code snippet below shows how to use the ContentExtractorType.Document content extractor. If the document is encrypted with a password and the SDK supports decrypting the document type, then a dialog prompting for the valid password is displayed in this example:
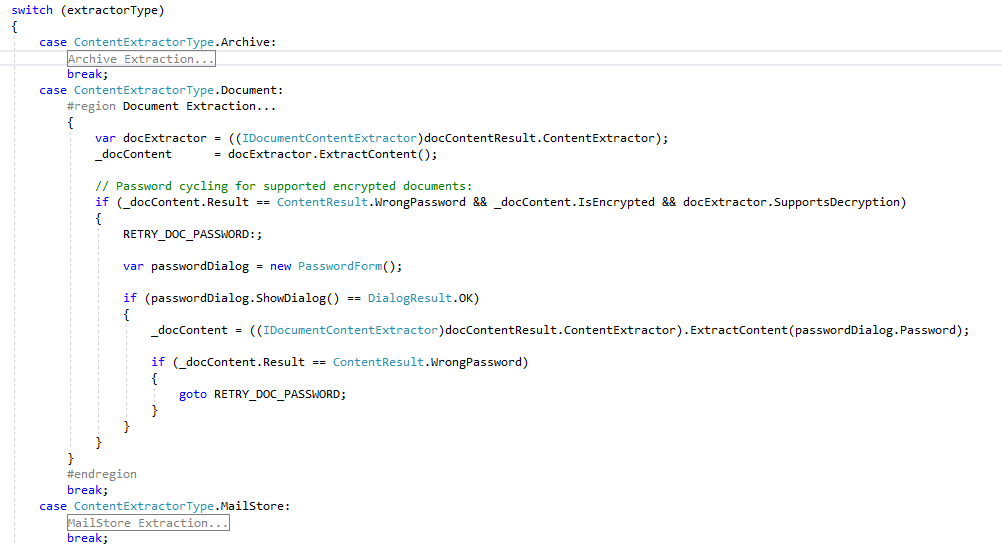
It is that simple. The returned '_docContent' object (DocumentContent class object) in the above code contains the extracted text, languages present in the extracted text, document attributes, metadata, embedded objects and attachments. All retrieved in one method call. The class diagram of the returned DocumentContent base class and special document content derived classes that offer extra extracted content for email, archive, mail store, PDF, and HTML formats:

The example C# sample projects distributed with the SDK show how to use all the content extractor types in addition to an example showing how to use DocumentIdentifier class to identify files in parallel. There are also several examples showing how to use the .NET PlatformWorker class to process a set of documents as a task, process a large archive as task, and process a mail store (.pst,.ost,.mbox) as a task.
See the 'API Reference' for detailed descriptions of all .NET SDK API classes.
The SDK can decrypt common office formats such as Microsoft Office 97-2003, Microsoft Office 2007-2016, Open Document Formats (OpenOffice and Libre Office), ZIP, 7Z, RAR, and PDF by cycling through a user supplied list of known passwords.
The SDK identifies many encrypted document formats. Knowing if a document is encrypted is useful for many reasons, such as:
- To get document passwords from key people leaving a company
- IT Security: verify that employees are encrypting their documents and following security guidelines
- To identify why content extraction failed on a particular document, e.g., if no valid passwords given to extract from an encrypted document or archive.
The Open Discover™ SDK is ideal technology for processing unstructured content for business applications such as:
- eDiscovery
- Corporate information governance
- Full-text search using SDK with open source Lucene.NET
- Text analytics/document concept clustering
- Enterprise search and content management
- Big Data, machine learning, AI, etc.
- Website crawling/full-text website search
Platform is an additional Open Discover .NET namespace that contains .NET classes that build upon the Open Discover SDK API. The Platform namespace offers a higher level implementation of document processing and also processed document output storage. Developers using Open Discover SDK or any competing SDK/API would need to implement such higher level processing classes themselves if they want to efficiently process 10's of 1000's of documents for full-text search, information governance, IT applications, eDiscovery applications, etc.
Due to the complexity of implementing the Open Discover Platform namespace and its various .NET classes, the Platform .NET namespace is only available to select customers for trial, select customers with prior knowledge and experience in regularly processing terabytes worth of documents.
DocumentTaskEngine is one such complex class in the Platform .NET namespace. DocumentTaskEngine class is a multi-threaded and very high performing document task processing engine. It is very fast at processing gigabytes worth of document sets, large archive containers, and large mail stores and storing the processed document output for easy post-processing tasks such as indexing for full-text search or bulk inserting processed data into a document database.
DocumentTaskEngine class is designed to:
- Process a set of documents as a single task - extract text, metadata, and attachments from documents including documents extracted from all containers (archive and mail store containers). Processing is not complete until all extracted container items and all extracted attachments are processed recursively, until all documents and extracted attachments are completely "unrolled".
- Process very large archives (7ZIP,ZIP,RAR,TAR, etc) as a single task, or optionally, partitioned into several partitions for distributed processing by several instances of DocumentTaskEngine.
- Process very large mail store containers (PST, OST,OST2013,MBOX) as a single task, or optionally, partitioned into several partitions for distributed processing by several instances of DocumentTaskEngine.
Besides full document processing mode (i.e., extracting text, metadata, and attachments until documents and their attachments are completely unrolled), DocumentTaskEngine class also has several other built-in processing modes that are useful for IT departments and information governance such as:
- Metadata scanning documents and container items (container items to 1st item level) - this includes extracting all metadata, identifying document file format, binary hashing documents, and also (optionally) calculating EDRM "content hash" on supported file formats such as emails and office documents. This includes all immediate container items.
- Metadata scanning documents and container items (no container items metadata scanned) - All input documents are metadata scanned like above mode, however, container items are not included. Container level metadata such as the number of container items in archive and mail store containers will be included in the container document metadata.
- File format identification and (optionally) binary and "content" hashing only of all documents in task input set.